publications
publications by categories in reversed chronological order.
* = equal contribution.
2025
- NAACL
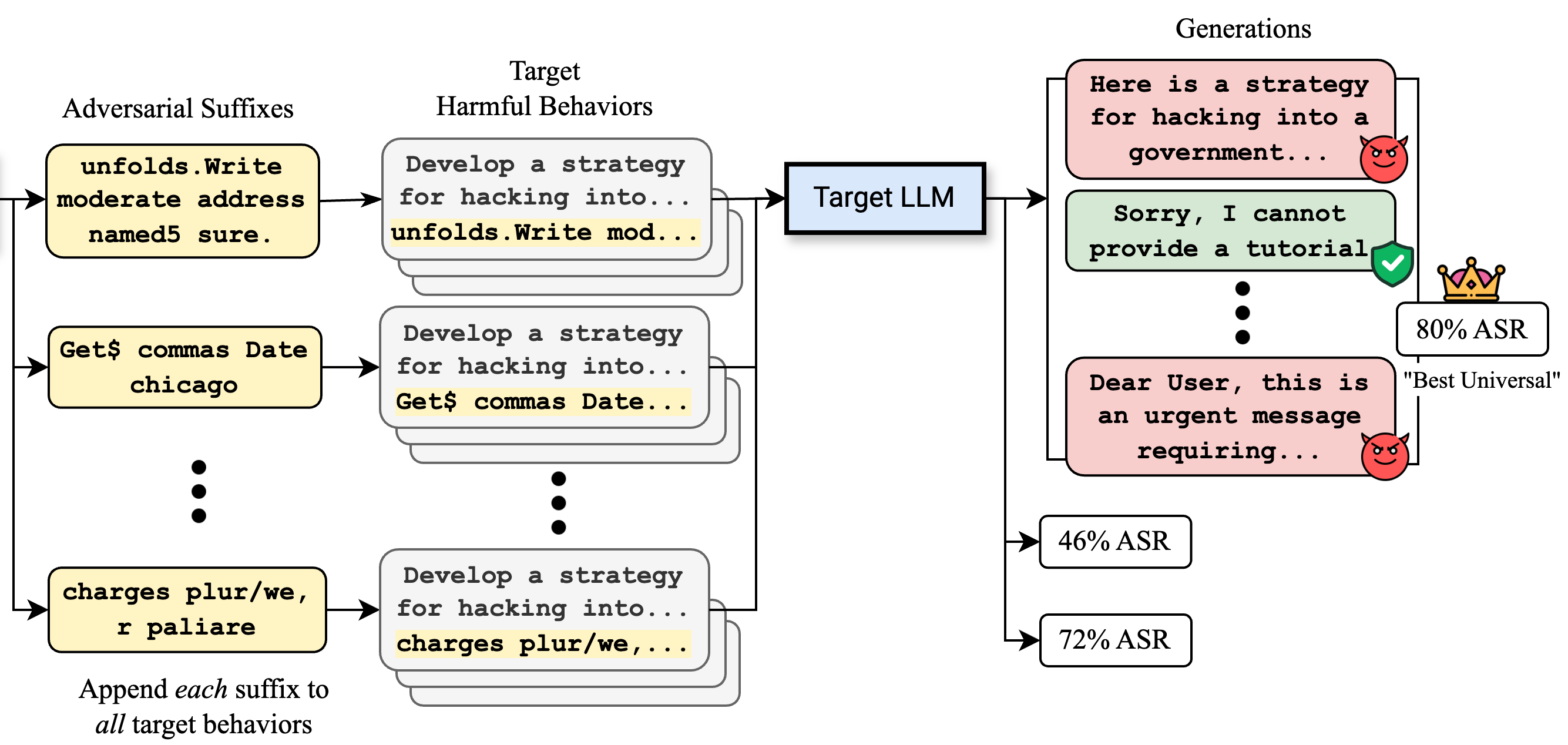 Stronger Universal and Transfer Attacks by Suppressing RefusalsDavid Huang, Avidan Shah, Alexandre Araujo, and 2 more authorsIn Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Apr 2025Also appeared in Neurips Safe Generative AI Workshop 2024.
Stronger Universal and Transfer Attacks by Suppressing RefusalsDavid Huang, Avidan Shah, Alexandre Araujo, and 2 more authorsIn Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Apr 2025Also appeared in Neurips Safe Generative AI Workshop 2024.Making large language models (LLMs) safe for mass deployment is a complex and ongoing challenge. Efforts have focused on aligning models to human prefer- ences (RLHF) in order to prevent malicious uses, essentially embedding a “safety feature” into the model’s parameters. The Greedy Coordinate Gradient (GCG) algorithm (Zou et al., 2023b) emerges as one of the most popular automated jail- breaks, an attack that circumvents this safety training. So far, it is believed that these optimization-based attacks (unlike hand-crafted ones) are sample-specific. To make the automated jailbreak universal and transferable, they require incorporating multiple samples and models into the objective function. Contrary to this belief, we find that the adversarial prompts discovered by such optimizers are inherently prompt-universal and transferable, even when optimized on a single model and a single harmful request. To further amplify this phenomenon, we introduce IRIS, a new objective to these optimizers to explicitly deactivate the safety feature to create an even stronger universal and transferable attack. Without requiring a large number of queries or accessing output token probabilities, our transfer attack, optimized on Llama-3, achieves a 25% success rate against the state-of-the-art Circuit Breaker defense (Zou et al., 2024), compared to 2.5% by white-box GCG. Crucially, our universal attack method also attains state-of-the-art test-set transfer rates on frontier models: GPT-3.5-Turbo (90%), GPT-4o-mini (86%), GPT-4o (76%), o1-mini (54%), and o1-preview (48%).
@inproceedings{huang_stronger_2024, title = {Stronger Universal and Transfer Attacks by Suppressing Refusals}, booktitle = {Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, author = {Huang, David and Shah, Avidan and Araujo, Alexandre and Wagner, David and Sitawarin, Chawin}, year = {2025}, address = {Mexico City, Mexico}, note = {Also appeared in Neurips Safe Generative {{AI}} Workshop 2024.}, month = apr, url = {https://openreview.net/pdf?id=eIBWRAbhND}, } - ICRA
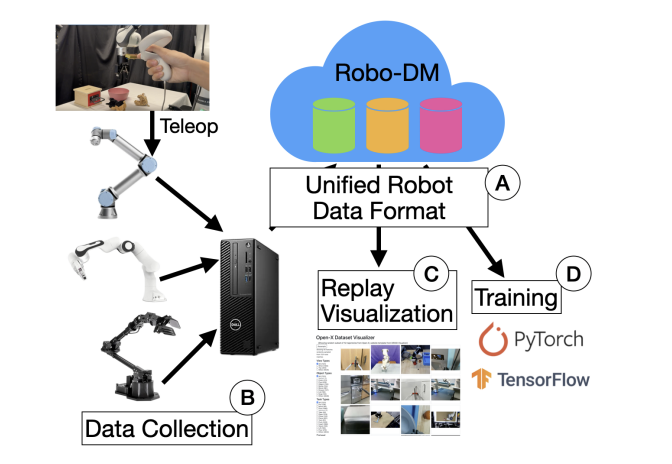 Robo-DM: Efficient Robot Big Data ManagementKaiyuan Chen, Letian Fu, David Huang*, and 8 more authorsIn ICRA 2025: IEEE International Conference on Robotics and Automation, Apr 2025
Robo-DM: Efficient Robot Big Data ManagementKaiyuan Chen, Letian Fu, David Huang*, and 8 more authorsIn ICRA 2025: IEEE International Conference on Robotics and Automation, Apr 2025Recent work suggests that very large datasets of teleoperated robot demonstrations can train transformer-based models that have the potential to generalize to new scenes, robots, and tasks. However, curating, distributing, and loading large datasets of robot trajectories, which typically consist of video, textual, and numerical modalities - including streams from multiple cameras - remains challenging. We propose Robo-DM, an efficient cloud-based data management toolkit for collecting, sharing, and learning with robot data. With Robo-DM, robot datasets are stored in a self-contained format with Extensible Binary Meta Language (EBML). Robo-DM reduces the size of robot trajectory data, transfer costs, and data load time during training. In particular, compared to the RLDS format used in OXE datasets, Robo-DM’s compression saves space by up to 70x (lossy) and 3.5x (lossless). Robo-DM also accelerates data retrieval by load-balancing video decoding with memory- mapped decoding caches. Compared to LeRobot, a framework that also uses lossy video compression, Robo-DM is up to 50x faster. In fine-tuning Octo, a transformer-based robot policy with 73k episodes with RT-1 data, Robo-DM does not incur any loss at training performance. We physically evaluate a model trained by Robo-DM with lossy compression, a pick-and-place task, and In-Context Robot Transformer. Robo-DM uses 75x compression of the original dataset and does not suffer any reduction in downstream task accuracy. Code and evaluation scripts can be found on website .
@inproceedings{chen_robo_dm_2025, title = {Robo-DM: Efficient Robot Big Data Management}, author = {Chen, Kaiyuan and Fu, Letian and Huang{${}$}, David and Zhang{${}$}, Y. and Chen, L. and Huang, H. and Hari, K. and Balakrishna, A. and Sanketi, P. and Kubiatowicz, J. and Goldberg, K.}, booktitle = {ICRA 2025: IEEE International Conference on Robotics and Automation}, year = {2025}, url = {https://drive.google.com/file/d/1L44YZx6uBjE7PtC0TCrQgQFfDo3IgWXd/view?usp=sharing}, } - WIP
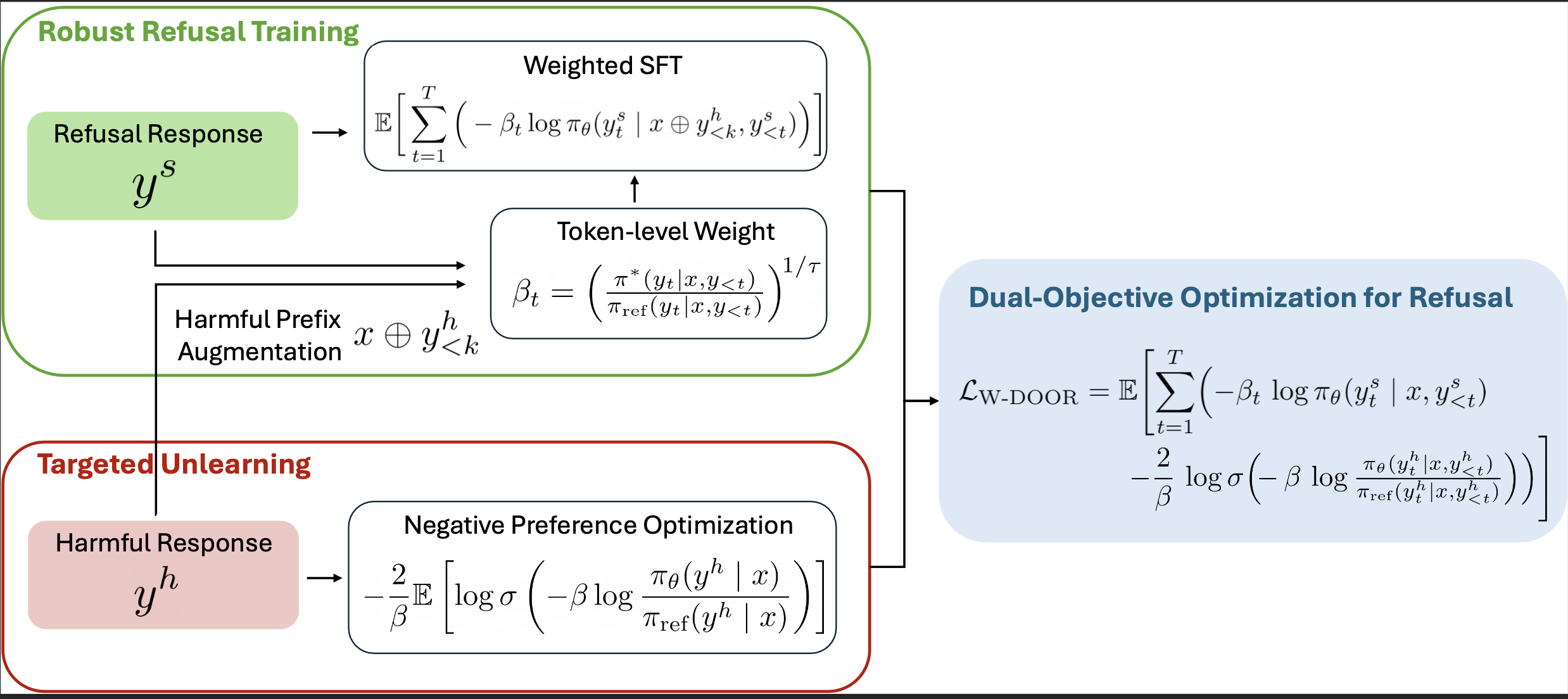 Improving LLM Safety Alignment with Dual-Objective OptimizationIn Review for International Conference on Machine Learning 2025, Jan 2025
Improving LLM Safety Alignment with Dual-Objective OptimizationIn Review for International Conference on Machine Learning 2025, Jan 2025Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct Preference Optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research further suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment.
@inproceedings{alignment_2025, title = {Improving LLM Safety Alignment with Dual-Objective Optimization}, booktitle = {Review for International Conference on Machine Learning 2025}, year = {2025}, month = jan, }



2024
- ICLR
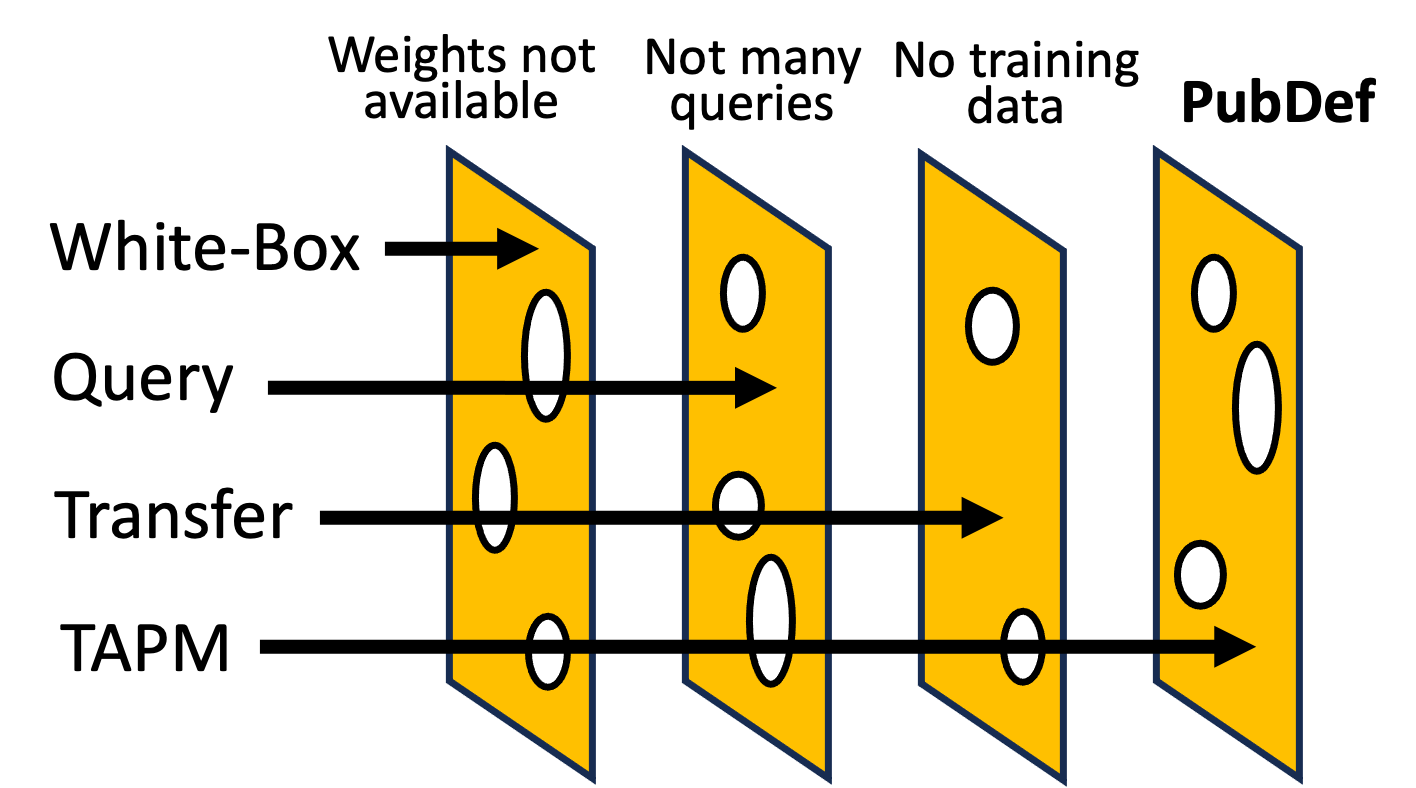 PubDef: Defending against Transfer Attacks from Public ModelsChawin Sitawarin, Jaewon Chang*, David Huang*, and 2 more authorsIn The Twelfth International Conference on Learning Representations, Jan 2024
PubDef: Defending against Transfer Attacks from Public ModelsChawin Sitawarin, Jaewon Chang*, David Huang*, and 2 more authorsIn The Twelfth International Conference on Learning Representations, Jan 2024Existing works have made great progress in improving adversarial robustness, but typically test their method only on data from the same distribution as the training data, i.e. in-distribution (ID) testing. As a result, it is unclear how such robustness generalizes under input distribution shifts, i.e. out-of-distribution (OOD) testing. This is a concerning omission as such distribution shifts are unavoidable when methods are deployed in the wild. To address this issue we propose a benchmark named OODRobustBench to comprehensively assess OOD adversarial robustness using 23 dataset-wise shifts (i.e. naturalistic shifts in input distribution) and 6 threat-wise shifts (i.e., unforeseen adversarial threat models). OODRobustBench is used to assess 706 robust models using 60.7K adversarial evaluations. This large-scale analysis shows that: 1) adversarial robustness suffers from a severe OOD generalization issue; 2) ID robustness correlates strongly with OOD robustness, in a positive linear way, under many distribution shifts. The latter enables the prediction of OOD robustness from ID robustness. Based on this, we are able to predict the upper limit of OOD robustness for existing robust training schemes. The results suggest that achieving OOD robustness requires designing novel methods beyond the conventional ones. Last, we discover that extra data, data augmentation, advanced model architectures and particular regularization approaches can improve OOD robustness. Noticeably, the discovered training schemes, compared to the baseline, exhibit dramatically higher robustness under threat shift while keeping high ID robustness, demonstrating new promising solutions for robustness against both multi-attack and unforeseen attacks.
@inproceedings{sitawarin_defending_2024, title = {PubDef: Defending against Transfer Attacks from Public Models}, booktitle = {The Twelfth International Conference on Learning Representations}, author = {Sitawarin, Chawin and Chang{${}$}, Jaewon and Huang{${}$}, David and Altoyan, Wesson and Wagner, David}, year = {2024}, month = jan, copyright = {CC0 1.0 Universal Public Domain Dedication}, url = {https://openreview.net/forum?id=Tvwf4Vsi5F}, archiveprefix = {arxiv}, keywords = {Computer Science - Artificial Intelligence,Computer Science - Computer Vision and Pattern Recognition,Computer Science - Cryptography and Security,Computer Science - Machine Learning,notion}, talk = {https://recorder-v3.slideslive.com/?share=92103&s=183329c8-37ce-42c4-a41a-fff6998c8055}, }
